
Why Use J*vascript slop Instead of Bash?
TL;DR - I hate the language that shall not be named so much that it made me master the sacred art of bash scripting, and build this entire website with it (along with some mystery ingredient)
Recently my laptop broke. IDK what the problem is but the important thing is that it contained all the latest versions of my projects (I use git like a sane person but there are still unpushed changes).
So with my midterms being in a week, like any self-respecting university student, I forgot about it and studied for my... SIKE! Fuck that, let's make a website.
Wait. Does this mean I'll finally be forced to write j*vascript? Hell no, I'd rather move to North Korea. I'd do anything not to use it.
Anything.
And I mean it.
Being the third world brokie that I am, I decided to use Github Pages for my "creative" "endeavours". Basically Github has this service that auto-deploys a repository into a website. For free. And with little effort too. All you need is:
Then just throw in an index.html and voila, you have yourself a beautiful looking websi-
naaaah it looks like shit
So let's fix that.
Even at the infancy of web, people much smarter than me and you combined, coincidentally had the exact same problem. So they invented... DSSSL... and FOSI... and some others, but they all sucked so instead, we prompt write CSS today. (istg llms are way too good at turning images into css)
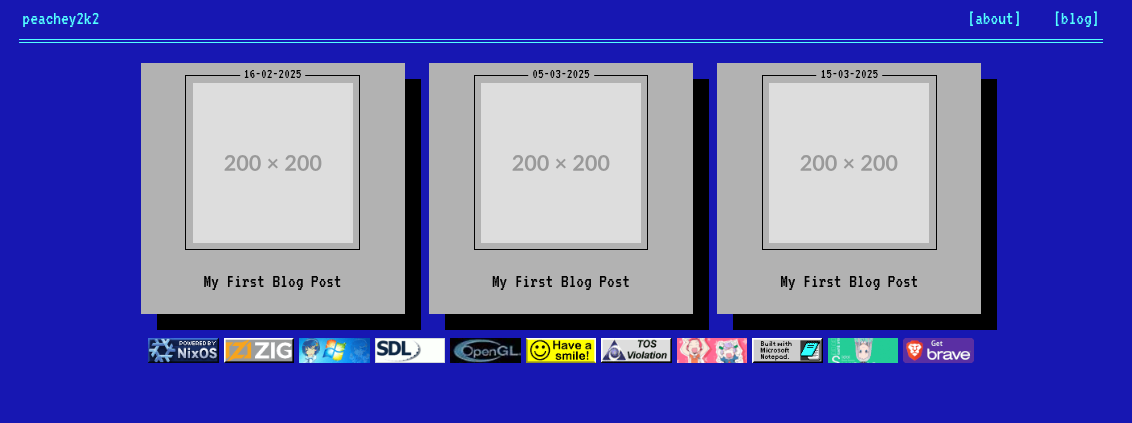
It looks quarter a decade older than I'd like but still passable.
Now we need a way to write blog posts in a more humane way, because my ass ain't writing raw html. We can use marked for this. Just fetch the .md files and put the fries in the bag.
let markdownDiv = document.createElement("div");
markdownDiv.id = "markdown-content";
document.getElementById("site-body").appendChild(markdownDiv);
fetch(blogList[curHash].filename)
.then(response => {
if (response.ok == false) throw new Error("Article not found");
return response.text();
})
.then(text => {
const infoRaw = text.substring(0, text.indexOf("---\n"));
info = INI.parse(infoRaw); // fuck json tbh
return text.substring(infoRaw.length + 4);
})
.then(markdown => {
markdownDiv.innerHTML = marked.use(markedExt).parse(markdown);
})
.catch(error => {
console.error("Error loading markdown:", error);
document.getElementById("markdown-content").innerHTML =
"Failed to load content.";
});EWWWWWWW GROSS. Get this vomit-inducing garbage language outta here! Well at least I don't have to deal with JSON and its allergy for trailing commas.
Jokes aside, you might have noticed that we're accessing the files using hashes (that we hold as url parameters) through an .ini file. Which I used to automatically generate with this lovely script:
#!/bin/sh
cwd="$(dirname $0)"
cd $cwd
fileAppend() {
echo "$1" >> "blog-list.ini"
}
echo "" > "blog-list.ini"
ls -1 "./blog" | while read file; do
if (echo $file | grep "\.md\$" > "/dev/null"); then
nameStripped="${file%.md}"
nameHash=$(echo $nameStripped | md5sum | head -c 8)
fileAppend "[$nameHash]"
fileAppend "filename = $file"
cat "blog/$file" | while read line; do
if [[ "$line" == "---" ]]; then
break
fi
fileAppend "$line"
done
fileAppend ""
fi
doneI'll give a brief explanation since shell scripting is somehow even harder to read than FP. Basically we read the beginning of every .md file (until "---") as an .ini file, and then merge all those key-value pairs into a single "blog-list.ini" file for easier access.
This is later used for indexing into each .md file like seen before:
fetch("/blog-list.ini")
.then(response => {
if (response.ok == false) throw new Error("Blog list not found");
return response.text();
})
.then(text => INI.parse(text))
.then(blogList => {
...But we can do better than that. We're still using j*vascript on the client like the average soydev stuck in SF hellhole, while we could generate all that html in the server instead. So let's start out mad crusade into the land of insanity with a simple change:
...
echo "" > "blog-list.ini"
ls -1 "./blog" | while read file; do
if (echo $file | grep "\.md\$" > "/dev/null"); then
nameStripped="${file%.md}"
nameHash=$(echo $nameStripped | md5sum | head -c 8)
fileAppend "[$nameHash]"
fileAppend "filename = $file"
cat "blog/$file" | while read line; do
if [[ "$line" == "---" ]]; then
mkdir -p "$out/b/$1"
cat "template/head.html" >> "$out/b/$nameHash.html"
echo '<div id="markdown-content">' >> "$out/b/$nameHash.html"
# slurps the rest of stdout (gets the remaining lines of the file)
${marked}/bin/marked -c "marked.js" >> "$out/b/$nameHash.html"
echo '</div>' >> "$out/b/$nameHash.html"
cat "template/tail.html" >> "$out/b/$nameHash.html"
marked -c "marked.js" > "b/$nameHash.html"
break
fi
fileAppend "$line"
done
fileAppend ""
fi
doneYes. marked has a CLI. We can push the rest of the file into it and in return, get a fully formatted html. Better yet, we can give it a config file (in the form of j*vascript, sadly, but don't worry, we'll get to that too) to automatically add some eyecandy.
We now have a website builder. At this point I figured all of this wasn't reproducible and deterministic enough, so there is only one feasible way this whole project can go:
{
inputs = {
nixpkgs.url = "github:NixOS/nixpkgs/24.11";
};
outputs = { self, nixpkgs }:
let
pkgs = import nixpkgs { system = "x86_64-linux"; };
marked = pkgs.callPackage ./packages/marked/package.nix {};
in {
devShell.default = pkgs.mkShell {
name = "website-dev";
packages = [
marked
pkgs.python3Minimal
];
};
packages.default = pkgs.stdenv.mkDerivation {
pname = "website";
version = "0.1.0";
src = ./.;
installPhase = ''
# it's way too long i won't put it here
...
''
};
apps.default = {
type = "app";
program = let
script = pkgs.writeShellScriptBin "run-server" ''
${pkgs.python3Minimal}/bin/python3 -m http.server 8000 --directory result/;
'';
in
"${script}/bin/run-server";
};
defaultPackage.x86_64-linux = self.packages.default;
defaultApp.x86_64-linux = self.apps.default;
};
}Perfect. Just as god intended.
I hear you ask "What about the code blocks that you've been (ab)using througout this blog post?" Well... highligh.js (which seemed like the best option) doesn't have a CLI by default, but there is a CLI version written by tzemanovic. It takes input from stdin and outputs to stdout. So our general pipeline for generating each post would now be like this:
marked -c [marked-config] | hljs >> [output]We now have no J*vascript running in the client. But there is still a slight issue. An itch that I can't seem to scratch off. The marked config file. I want it GONE. I DON'T WANNA SEE IT. BEGONE FOUL BEAST!
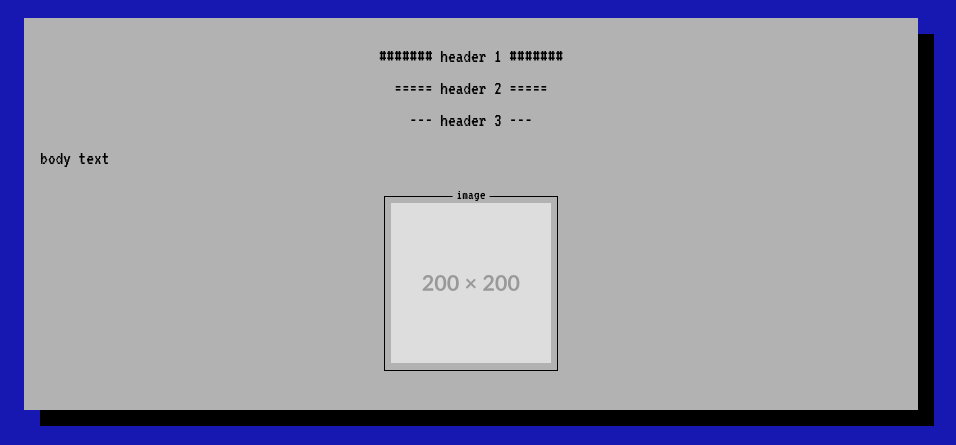
translateMarkdown() {
# images
${pkgs.perl}/bin/perl -pe 's/!\[([^\]]*)\]\(([^\)]*)\)/"
<div class=\"centered-div\">
<div class=\"blog-image\" style=\"display: inline-flex\">
<img src=\"$2\">
<div class=\"blog-image-text\">
$1
<\/div>
<\/div>
<\/div>"
/gsme' |
# headings
${pkgs.perl}/bin/perl -pe 's/^# (.*)/<h1 class="centered">####### $1 #######<\/h1>/g' |
${pkgs.perl}/bin/perl -pe 's/^## (.*)/<h2 class="centered">===== $1 =====<\/h2>/g' |
${pkgs.perl}/bin/perl -pe 's/^### (.*)/<h3 class="centered">--- $1 ---<\/h3>/g' |
# code blocks
${pkgs.perl}/bin/perl -0777 -pe 's/^```([^\n]*?)\n(.*?)```/"
<div class=\"centered-div\">
<div class=\"blog-image\" style=\"display: inline-flex\">
<pre style=\"margin: 8px\"><code class=\"language-$1\">$2<\/code><\/pre>
<div class=\"blog-image-text\">
$1
<\/div>
<\/div>
<\/div>"/gsme' |
${pkgs.multimarkdown}/bin/multimarkdown
}Okay, I'll put the sarcasm aside and be honest for once. I didn't actually include this function in my bash builder since it'd make it way harder to read and expand upon. Yes my masochism actually does have a limit.
There are a few other things I did, such as a Github workflow to auto-deploy and a script to build images for embeds using imagemagick, but this post is already long enough.
If you're curious on the full code, you can find it in this repo.










